

A 70-billion-parameter LLM needs about 140GB of VRAM for FP16 inference (2 bytes per parameter), or roughly 35–40GB when quantized to 4-bit. Training needs 1.5–4x more than inference for optimizer states and gradients. As a quick rule, budget ~2GB of VRAM per 1B parameters at FP16 for inference — then add overhead for the KV cache and context.
VRAM is the single most important spec when picking a GPU for an LLM: it decides whether a model fits at all, before speed ever matters. This guide gives you the formula, a lookup table by model size, and the right GPU for each case.
The VRAM rule of thumb
You can estimate VRAM for model weights with one formula:
VRAM (GB) ≈ parameters (billions) × bytes per parameter
Bytes per parameter depend on precision:
| Precision | Bytes / parameter |
|---|---|
| FP32 (full) | 4 |
| FP16 / BF16 (half) | 2 |
| INT8 (8-bit) | 1 |
| INT4 (4-bit) | 0.5 |
So a 7B model at FP16 needs about 7 × 2 = 14GB just for weights. A 70B model at FP16 needs 70 × 2 = 140GB.
This covers the model weights only. Real inference also needs memory for the KV cache (which grows with context length and batch size) and some activation overhead — typically add 15–25% on top for short contexts, more for long ones. For a safe estimate, multiply the weight figure by ~1.2.
VRAM requirements by model size
Here’s the lookup table for common open model sizes. Figures are weight-only estimates — add ~20% for inference overhead.

| Model size | FP16 (weights) | INT8 | INT4 | Single-GPU fit |
|---|---|---|---|---|
| 7B | ~14GB | ~7GB | ~3.5GB | RTX 4090 (FP16) |
| 13B | ~26GB | ~13GB | ~6.5GB | RTX 4090 (INT8/INT4), A100 (FP16) |
| 34B | ~68GB | ~34GB | ~17GB | A100/H100 80GB (FP16) |
| 70B | ~140GB | ~70GB | ~35GB | H200 (INT8), B200 (INT8); multi-GPU for FP16 |
| 405B | ~810GB | ~405GB | ~203GB | Multi-GPU cluster only |
The pattern is clear: at FP16, a 70B model exceeds any single current GPU, but in 4-bit it drops to ~35GB and fits comfortably on an 80GB card. Quantization is what makes large models runnable on modest hardware.
Inference vs training: very different budgets
Inference and training have completely different memory profiles. This is where most VRAM estimates go wrong.
Inference needs weights + KV cache + a little overhead. Our ~2GB-per-1B FP16 rule applies here.
Full training needs far more — typically 16–20GB of VRAM per 1B parameters with an Adam optimizer, because you store the weights plus gradients, optimizer states (two per parameter for Adam), and activations. That’s why fully training even a 7B model can demand 100GB+ of VRAM, well beyond a single consumer card.
Parameter-efficient fine-tuning (LoRA, QLoRA) sidesteps this. Instead of updating all weights, you train small adapter layers and keep the base model frozen — often quantized. QLoRA can fine-tune a 70B model on a single 48GB or 80GB GPU. If your goal is fine-tuning on a budget, this is the technique that makes it possible; see our guide on fine-tuning an LLM on a cloud GPU and the LoRA vs QLoRA breakdown.
How quantization cuts VRAM
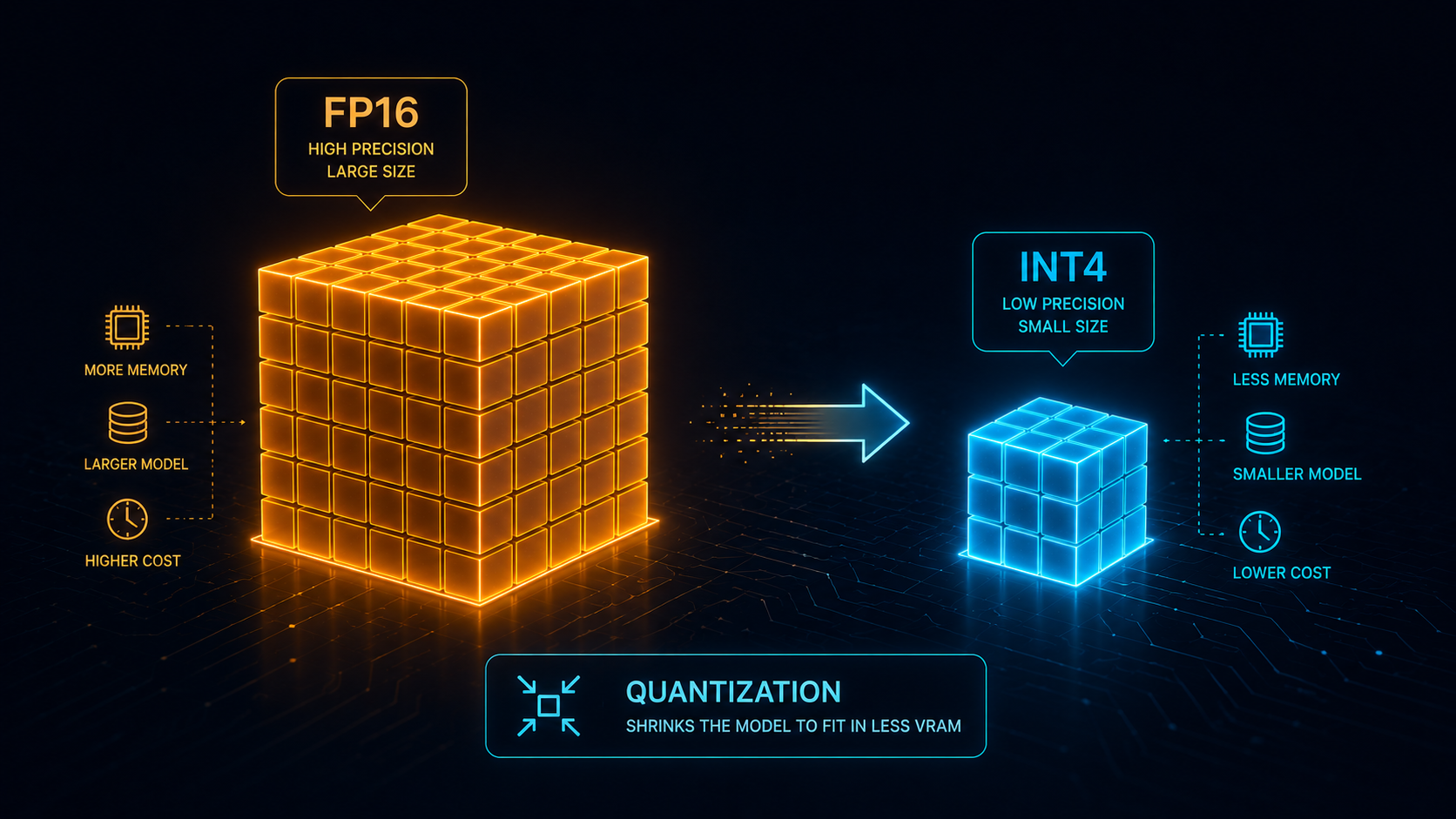
Quantization stores model weights at lower precision, shrinking VRAM 2–4x:
- INT8 halves memory versus FP16 with minimal quality loss for most models.
- INT4 cuts it to a quarter — a 70B model drops from ~140GB to ~35GB — enabling single-GPU inference, with a modest quality trade-off that’s acceptable for many tasks.
The trade-off: lower precision can reduce output quality on complex reasoning or long-form tasks. INT8 is usually safe; INT4 is excellent for cost-sensitive inference but worth testing against your use case. The practical upside is large — quantization often eliminates the need for a second GPU entirely, removing interconnect overhead and cost.
Which GPU for which model
Matching VRAM to your model size and precision gives a clear shortlist:
- RTX 4090 (24GB) — 7B at FP16, 13B quantized. Best price-per-FLOP for small-model inference.
- A100 / H100 (80GB) — up to ~34B at FP16, 70B quantized. The workhorses for most teams.
- H200 (141GB) — single-card 70B at INT8, or large-context inference. Strong for memory-bound serving.
- B200 (192GB) — 70B with headroom, larger models quantized. The latest Blackwell card for high-end work.
For full specs and current rental prices on each, see our cloud GPU models guide and H100 guide.
Single-GPU vs multi-GPU

When a model doesn’t fit on one card, you go multi-GPU — but be aware of two things.
First, VRAM does not automatically pool. Two 80GB GPUs don’t give you a seamless 160GB; the model must be split across them using tensor or pipeline parallelism, which the framework (vLLM, DeepSpeed, etc.) handles.
Second, crossing the single-GPU boundary adds interconnect overhead. Communication runs over NVLink or the network, and misconfiguration can cut throughput by 20–40%. Staying on a single GPU — even if it means quantizing — is often faster and simpler than splitting across two.
The takeaway: prefer the smallest setup that fits. Quantizing a 70B model to run on one 80GB GPU usually beats running it in FP16 across two.
The bottom line
Start with the rule — ~2GB per 1B parameters at FP16 for inference — then adjust for precision and overhead. A 70B model needs 140GB at FP16 but only ~35GB at 4-bit, so quantization is your main lever for fitting big models on affordable hardware. Size the GPU to the model, not the other way around, and avoid overprovisioning: many workloads that teams default to running on H100 clusters fit comfortably on a single quantized card.
FAQs
How much VRAM do I need for a 7B model? About 14GB at FP16 (weights only), or ~7GB at INT8 and ~3.5GB at INT4. A single RTX 4090 (24GB) runs a 7B model comfortably at FP16 with room for context.
Can I run a 70B model on one GPU? Yes, if you quantize it. At 4-bit a 70B model needs ~35GB, which fits on an 80GB A100/H100. In full FP16 it needs ~140GB and requires multiple GPUs or a high-memory card like the H200/B200.
Does quantization hurt model quality? INT8 has minimal impact on most models. INT4 introduces a modest quality trade-off that’s acceptable for many tasks but worth testing on complex reasoning or long-form generation. The VRAM savings (2–4x) usually outweigh the cost.
How much more VRAM does training need versus inference? Full training typically needs 1.5–4x more — roughly 16–20GB per 1B parameters with an Adam optimizer, versus ~2GB per 1B for FP16 inference. Parameter-efficient methods like QLoRA cut this dramatically.